基于Python的企業(yè)管理系統(tǒng) 整合爬蟲、數(shù)據(jù)分析與可視化的設計與開發(fā)

在當前數(shù)字化浪潮下,企業(yè)對于高效、智能的管理系統(tǒng)需求日益增長。本文旨在探討一個基于Python技術的綜合性企業(yè)管理系統(tǒng)的設計與開發(fā)。該系統(tǒng)不僅涵蓋了商家與客戶的核心管理功能,還創(chuàng)新性地集成了Python網(wǎng)絡爬蟲、數(shù)據(jù)分析與可視化模塊,旨在為企業(yè)決策提供數(shù)據(jù)驅動的支持,并可作為計算機專業(yè)畢業(yè)設計的優(yōu)秀范例。
一、 系統(tǒng)總體設計
系統(tǒng)的核心目標是構建一個模塊化、可擴展的企業(yè)管理平臺。整體架構采用經(jīng)典的三層架構(表示層、業(yè)務邏輯層、數(shù)據(jù)訪問層),主要功能模塊包括:
- 商家與客戶關系管理(SCRM)模塊:這是系統(tǒng)的基石。實現(xiàn)商家信息、客戶檔案的錄入、查詢、修改與統(tǒng)計分析。通過Python的Django或Flask等Web框架構建后端接口,并利用前端技術(如HTML、CSS、JavaScript及Vue.js/React等框架)實現(xiàn)用戶友好的交互界面。
- Python爬蟲數(shù)據(jù)采集模塊:此模塊是企業(yè)獲取外部市場數(shù)據(jù)的關鍵。利用
Scrapy、BeautifulSoup、Requests等庫,設計可配置的爬蟲任務,定向抓取行業(yè)新聞、競品信息、市場價格、公開的工商數(shù)據(jù)等。采集的數(shù)據(jù)經(jīng)過清洗后,存入系統(tǒng)數(shù)據(jù)庫,為后續(xù)分析提供原料。
- 數(shù)據(jù)分析與處理核心模塊:這是系統(tǒng)的“智慧大腦”。利用
Pandas、NumPy等庫對內部業(yè)務數(shù)據(jù)(如銷售、庫存、財務)和外部爬取數(shù)據(jù)進行整合、清洗、轉換與計算。實現(xiàn)業(yè)務關鍵指標(KPI)的自動計算、趨勢分析、關聯(lián)性挖掘等。
- 數(shù)據(jù)可視化與報表模塊:決策者需要直觀的洞察。此模塊利用
Matplotlib、Seaborn、Plotly,特別是Pyecharts或集成ECharts,將分析結果轉化為豐富的圖表,如銷售儀表盤、客戶分布地圖、趨勢折線圖、關聯(lián)熱力圖等。支持自定義報表生成與導出。
- 系統(tǒng)管理與安全模塊:負責用戶權限控制、操作日志記錄、數(shù)據(jù)備份與系統(tǒng)配置,確保數(shù)據(jù)安全與操作合規(guī)。
二、 關鍵技術實現(xiàn)
- 開發(fā)環(huán)境與工具:Python 3.8+, IDE(PyCharm或VSCode), 數(shù)據(jù)庫(MySQL/PostgreSQL或MongoDB), 版本控制(Git)。
- 后端開發(fā):采用Django(功能全面,自帶ORM和Admin)或Flask(輕量靈活)框架。Django REST framework用于構建RESTful API,實現(xiàn)前后端分離。
- 數(shù)據(jù)爬蟲實現(xiàn):設計可配置的爬蟲調度器,管理多個爬蟲任務的啟動、停止與異常處理。重點處理反爬策略(如設置請求頭、使用代理IP、模擬登錄等),并遵守
robots.txt協(xié)議,確保合法合規(guī)采集。
- 數(shù)據(jù)分析流水線:構建自動化的數(shù)據(jù)處理流水線。使用
Pandas進行數(shù)據(jù)操作,結合Scikit-learn進行簡單的預測模型訓練(如銷售預測),并將處理結果緩存或持久化存儲以提高響應速度。
- 前后端交互與可視化:前端通過Axios等工具調用后端API獲取數(shù)據(jù)。可視化圖表通過API獲取JSON格式的數(shù)據(jù)動態(tài)渲染,實現(xiàn)交互式數(shù)據(jù)分析體驗。
三、 畢業(yè)設計亮點與數(shù)據(jù)處理價值
作為計算機畢業(yè)設計,本項目具有以下亮點:
- 綜合性:融合了Web開發(fā)、數(shù)據(jù)采集、數(shù)據(jù)處理、機器學習(基礎)和數(shù)據(jù)可視化等多個計算機核心領域知識。
- 實用性:解決企業(yè)管理中的真實痛點,項目成果具有直接的應用價值。
- 技術棧前沿:使用了Python生態(tài)中主流且活躍的技術庫,體現(xiàn)了良好的技術選型能力。
- 數(shù)據(jù)驅動:展示了從數(shù)據(jù)采集到洞察呈現(xiàn)的完整數(shù)據(jù)價值鏈,體現(xiàn)了現(xiàn)代企業(yè)系統(tǒng)的智能化特征。
在計算機數(shù)據(jù)處理方面,本項目完整實踐了數(shù)據(jù)生命周期管理:
- 數(shù)據(jù)采集:多源(內部+外部)異構數(shù)據(jù)獲取。
- 數(shù)據(jù)存儲與整合:結構化與非結構化數(shù)據(jù)的存儲方案設計。
- 數(shù)據(jù)清洗與預處理:處理缺失值、異常值、數(shù)據(jù)格式標準化。
- 數(shù)據(jù)建模與分析:運用統(tǒng)計方法與基礎算法挖掘數(shù)據(jù)價值。
- 數(shù)據(jù)可視化與解釋:將復雜數(shù)據(jù)結果以直觀方式呈現(xiàn),輔助商業(yè)決策。
四、 與展望
本文設計的基于Python的企業(yè)管理系統(tǒng),通過將傳統(tǒng)的業(yè)務管理與現(xiàn)代的數(shù)據(jù)智能技術相結合,為企業(yè)提供了一個一體化的解決方案。它不僅提升了日常運營效率,更重要的是通過數(shù)據(jù)爬蟲與可視化分析,賦予了企業(yè)前瞻性的市場洞察力和決策支持能力。對于開發(fā)者而言,該項目是掌握全棧開發(fā)與數(shù)據(jù)處理技能的絕佳實踐;是邁向數(shù)字化轉型的堅實一步。可進一步探索集成更復雜的AI模型、實現(xiàn)實時流數(shù)據(jù)處理、以及向微服務架構演進,以應對更大規(guī)模與更復雜的業(yè)務挑戰(zhàn)。
最新產品

西班牙吉普斯夸省圣塞巴斯蒂安醫(yī)院RAKS計算機服務器部門與數(shù)據(jù)處理中心的角色與價值
MATLAB計算機仿真實現(xiàn)QPSK調制解調系統(tǒng)及數(shù)據(jù)處理分析

計算機數(shù)據(jù)處理中云計算技術的應用
交互設計中的轉移策略 計算機數(shù)據(jù)處理的智能分流

2018年大數(shù)據(jù)智能搜索專業(yè)課題項目 計算機數(shù)據(jù)處理的創(chuàng)新與實踐
Python從零到數(shù)據(jù)分析與可視化 終極保姆級全流程指南
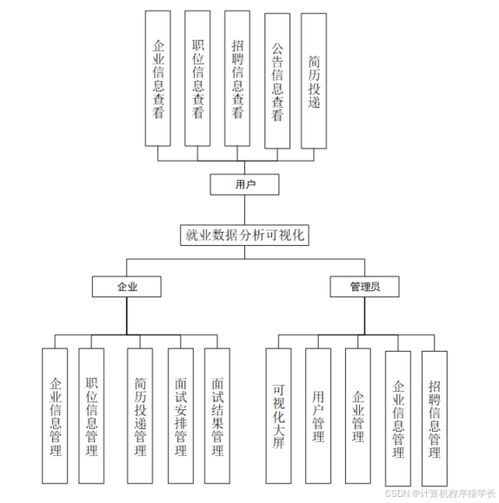
基于Python的河南省大學生就業(yè)數(shù)據(jù)分析與可視化系統(tǒng)設計與實現(xiàn)

計算機在轉動慣量實驗數(shù)據(jù)處理中的應用
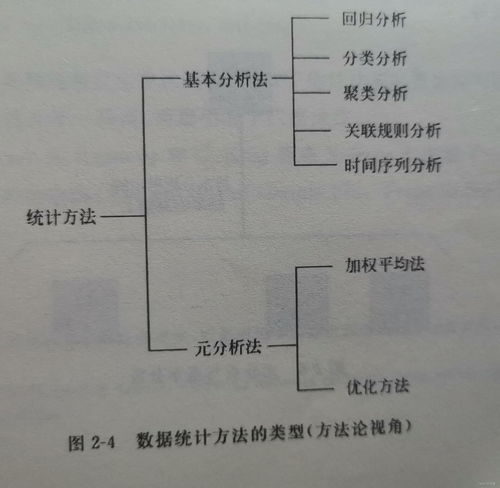
大數(shù)據(jù)概率理論基礎 構建海量數(shù)據(jù)處理的數(shù)學核心
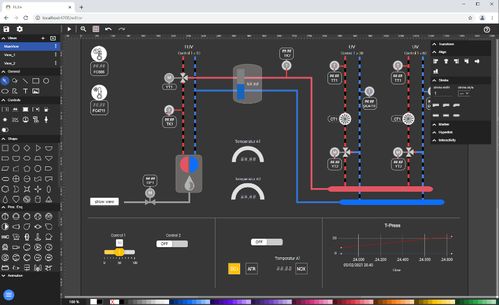
賦能工業(yè)未來 FUXA攜手ARMxy嵌入式計算機,打造數(shù)字化轉型可視化解決方案